協同過濾是一種解決用戶與產品之間關係的常見問題的方法。這種方法可以用於推薦電影、產品、新聞文章等,其核心思想是根據用戶的歷史行為(例如觀看電影、購買產品)來推斷用戶的興趣,然後向用戶推薦與其興趣相似的其他產品或項目
協同過濾方法的關鍵基本思想是潛在因子(latent factors)。以Netflix的例子,我們假設有一位用戶喜歡老的、充滿動作的科幻電影,我們藉由協同過濾,可以對其評分,然後藉由看看哪些潛在因子是有用的。
以下藉由movie lens 提供的資料,來跑跑看
因為原始資料格式很難做聯想,所以講師轉成以下表格
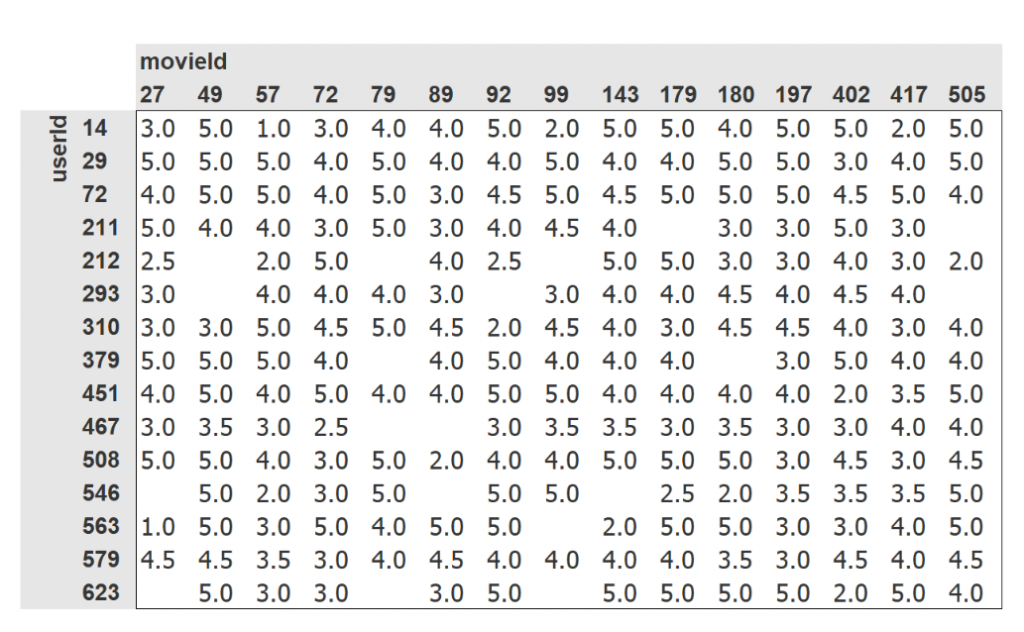
可以看到同一個user 對不同電影的評分
藉此我們可以找到不同user對電影的評價是類似的
但在這邊,僅憑電影的id,我們無法判斷這是什麼樣的電影
試想一下,如果電影有一些特徵的話,我們是否可以更容易的了解這是什麼樣的電影?
講師舉了The Last Skywalker來當例子,而特徵的範圍在 -1 到 +1 之間,其中正數表示更高程度的匹配,負數表示較低程度的匹配。而這些類別包括科幻、動作和老電影,那麼我們可以用數字向量來表示電影 "The Last Skywalker":
last_skywalker = np.array([0.98, 0.9, -0.9])
在這個向量中,我們將這部電影評為非常適合科幻(0.98)、非常適合動作(0.9)和非常不適合老電影(-0.9)
同樣地,我們可以表示一位喜歡現代科幻動作電影的用戶:user1 = np.array([0.9, 0.8, -0.6])
要知道2個向量是否相似,可以計算向量內積
(user1 * last_skywalker).sum() = 2.142
這個匹配度分數表示該用戶對於電影 "The Last Skywalker" 的喜好程度,數值越高表示越匹配,越可能喜歡這部電影。這種方法可以用來預測用戶對於不同電影的評分或喜好程度。
如果有另一部電影 "Casablanca",並使用一個向量來表示它:
casablanca = np.array([-0.99, -0.3, 0.8])
這個向量表示了電影 "Casablanca" 在不同類別(可能是類型、年齡、導演等)上的相關性,例如它對於科幻、動作和老電影的相關程度。
接下來,我們可以計算這個用戶 (user1) 與電影 "Casablanca" 之間的匹配度,同樣的方式是將兩個向量進行點積運算,然後將結果相加:
(user1 * casablanca).sum() = -1.611
這個匹配度分數表示用戶1對於電影 "Casablanca" 的喜好程度,數值為負值表示較不匹配,可能不太喜歡這部電影。點積運算可以幫助我們量化用戶和電影之間的相似性或匹配程度。
但這些喜好程度都是我們假設的,那實務上怎麼找出這些潛在因子呢?
這種方法的第一步是隨機初始化一些參數。
這些參數將是每個用戶和電影的一組潛在因子。我們必須決定要使用多少個潛在因子。
那如何選擇這些因子的數量呢?
我們先暫時使用5個。因為每個用戶都會有一組這些因子,每部電影也會有一組這些因子,所以我們可以將這些隨機初始化的值顯示在用戶和電影旁邊的交叉表中,然後我們可以填入這些組合的內積
如下圖,user 旁邊都有5個因子,這可能在描述這個用戶的特徵(非電影特徵)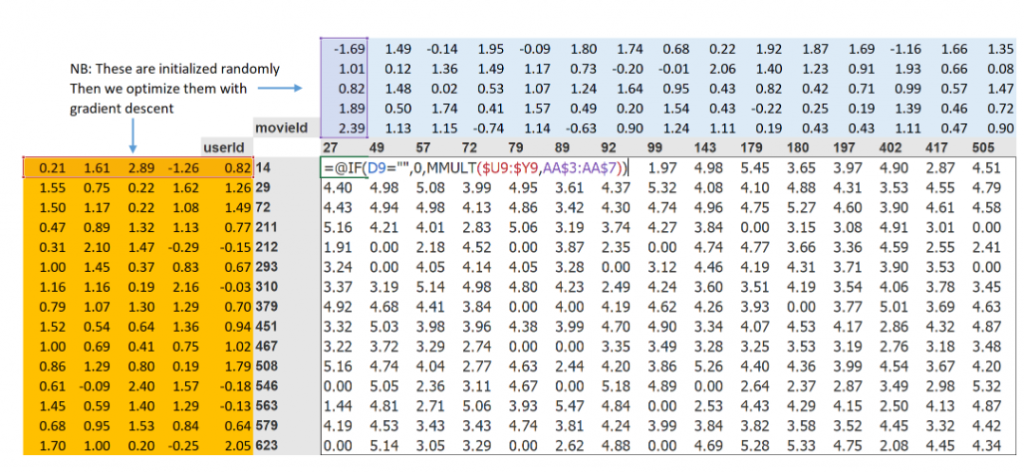
第二步是計算我們的預測。這邊就先用之前計算每部電影與每個用戶的內積來做到這一點。例如,如果第一個潛在用戶因子表示用戶有多喜歡動作片,而第一個潛在電影因子表示電影中是否有很多動作,那麼它們的乘積將在以下情況下特別高:如果用戶喜歡動作片,而電影中有很多動作,或者如果用戶不喜歡動作片,而電影中沒有動作。另一方面,如果存在不匹配(用戶喜歡動作片但電影不是動作片,或者用戶不喜歡動作片但電影是動作片),則內積來將非常低。
第三步是計算我們的loss值。我們可以定義一下我們的損失函數;這邊先用MSE( mean squared error),因為這是一種合理表示預測準確度的方式之一。
設定好這些後,我們可以使用隨機梯度下降來優化我們的參數(潛在因子),以使損失最小化。
在每個步驟中,隨機梯度下降優化器將使用點積計算每部電影與每個用戶之間的匹配度,並將其與每個用戶對每部電影的實際評分進行比較。
然後計算這個值的導數,並通過learning rate乘以這個值來調整權重。經過多次執行此操作後,損失將變得越來越小,推薦也將變得越來越好。
要使用通常的Learner.fit函數,我們需要將數據轉換為DataLoaders
知道該怎麼做後,就來看code吧!
首先先把數據拼成以下的樣子
創建user及movie 張量
n_users = len(dls.classes['user'])
n_movies = len(dls.classes['title'])
n_factors = 5
user_factors = torch.randn(n_users, n_factors)
movie_factors = torch.randn(n_movies, n_factors)
首先,我們知道要計算特定電影和用戶的結果,需要查找該電影在電影潛在因子矩陣中的索引以及該用戶在用戶潛在因子矩陣中的索引,然後進行潛在因子向量的點積操作。但深度學習模型並不知道如何執行索引查找操作,它們只知道如何執行矩陣乘法和激活函數。
為了解決這個問題,我們可以將索引查找操作表示為矩陣乘法。這裡的關鍵是將索引替換為一個獨熱編碼向量。以下展示了當我們將一個向量乘以一個表示索引3的獨熱編碼向量時會發生什麼情況:
one_hot_3 = one_hot(3, n_users).float()
user_factors.t() @ one_hot_3
# output 為 tensor([-1.2493, -0.3099, 1.4229, 0.0840, 0.4132])
user_factors[3]
# output 為 tensor([-0.4586, -0.9915, -0.4052, -0.3621, -0.5908])
所以如果我們對每個向量都做一樣的事,我們會得到一個矩陣,只是這樣比較沒效率。
那應該怎麼改善呢? 這邊就提到了一個概念叫Embeding。
當我們需要表示多個索引時,使用獨熱編碼會產生一個矩陣,其中每行都是一個索引的獨熱編碼向量。不過這樣樣的表示方法會佔用大量內存和計算時間,特別是當索引的範圍很大時。
為了解決這個問題,Embedding就出現了。Embedding可以將索引直接映射為相應的向量,而無需獨熱編碼和矩陣相乘的運算。這樣做節省了大量的內存和計算時間,同時保持了模型的效率。
同時Embedding設計使得它們在計算梯度時,可以保持與one-hot encoding相同的結果,這樣可以無縫地集成到深度學習模型中。這種特殊的嵌入層可以實現直接通過整數索引來訪問嵌入向量,同時保持對梯度的適當計算。這使得模型訓練過程更加高效且易於實現。
講了這麼多學術上的理論,實務上應該怎麼做呢?
例如NLP 要轉成詞向量我們才容易操作,也才能用SGD 等等的方法找出相關性
但是在這邊我們並沒有這些所謂的詞向量,那我們的電影要怎麼描述他呢?
我們可以先初始五個隨機參數,然後讓我們的模型用SGD 等等的方法計算後,慢慢調整。
一開始,這些數字沒有任何意義,因為我們是隨機選擇它們的,但到訓練結束時,它們就會有意義。
透過了解有關用戶和電影之間關係的現有數據,在沒有任何其他資訊的情況下,我們將看到它們仍然獲得一些重要的特徵,並且可以將大片與獨立電影、動作電影與愛情電影等區分開來。
接下來就要開始創建我們的模型了,下一篇待續!


 iThome鐵人賽
iThome鐵人賽